Nella primavera del 2015 abbiamo effettuato una riunione con un nostro cliente storico per riprogettare alcune componenti del suo parco applicativo, che ha le seguenti caratteristiche:
- applicativi differenti, ognuno con le sue informazioni (parco dati);
- ogni applicativo gestisce le informazioni e il modo di reperirle in maniera differente;
- l’utente deve conoscere i percorsi di ricerca specifici per ogni applicativo;
- i dati sono disomogenei tra gli applicativi, di conseguenza per trovare o gestire una determinata informazione può rendersi necessario effettuare ricerche su più applicativi.
Nel corso della riunione è emersa l’idea di creare un motore ricerca semantico Google style per valorizzare e facilitare la gestione dell’enorme insieme di informazioni memorizzate e gestite dai vari applicativi:
- oltre 1000 servizi;
- applicazioni e integratori per un totale di 1200 installazioni;
- oltre 13 milioni di anagrafiche.
Il motore di ricerca è una soluzione un po’ fuori dagli schemi:
- l’utente ricerca un’informazioni sui dati di tutti gli applicativi contemporaneamente; è poi il motore di ricerca a suggerire all’utente su quali applicativi specifici è presente l’informazione ricercata.
- è possibile, attraverso il motore di ricerca, aprire l’applicativo che gestisce o contiene l’informazione, facilitando e velocizzando il lavoro quotidiano dell’utente.
Per ottenere un risultato analogo si dovrebbe riprogettare ed integrare gli applicativi con costi decisamente superiori. Il motore di ricerca fornisce una nuova modalità di ricerca mantenendo le logiche di scrittura e l’indipendenza delle applicazioni.
Perché un motore di ricerca semantico? Le informazioni hanno un significato specifico all’interno degli applicativi di provenienza. Il motore di ricerca deve mantenere questa peculiarità e contemporaneamente utilizzarla per raggruppare e categorizzare le informazioni. Le tecnologie semantiche sono utili per raggiungere l’obiettivo in quanto, da un lato consentono di creare un modello di alto livello con all’interno tutti i significati attribuibili alle informazioni e dall’altro permettono di mappare sul modello le informazioni gestite dai sistemi, così da renderle omogenee per l’utilizzatore finale. Ad esempio, il concetto di anagrafica della persona è unico, ma le singole istanze sono trattate differentemente da applicativo ad applicativo (informazioni gestite, persistenza, … ): quando un motore di ricerca le indicizza, deve riconoscere che si tratta di anagrafiche di persona e, nel caso, di una stessa persona.
Il risultato ottenuto è una visione dei dati ad alto livello che mantiene allo stesso tempo l’eterogeneità delle fonti dei dati.
Il supporto dell’approccio semantico consente inoltre di mettere le informazioni in relazione le une con le altre. Ad esempio: una persona ha un indirizzo inerente ad una città; la città, a sua volta, è un concetto legato a molte altre informazioni . Si crea quindi un grafo navigabile di relazioni. Il grafo è estendibile senza modificare le informazioni indicizzate.
In questo modo è possibile eseguire ricerche su informazioni di tipo differente evitando la replicazione. Ad esempio: cercando “Imola”, si può ottenere Imola come città, ma navigando il grafo si possono ottenere tutte le aziende che hanno delle sedi a Imola e quindi le persone che vi lavorano.
Utilizzando un motore di ricerca tradizionale, si sarebbero potuti ottenere risultati analoghi mettendo in ogni blocco di informazioni anche le altre informazioni ad esso correlate, ad esempio indicizzando le anagrafiche assieme alle informazioni sulla città, l’azienda in cui si lavora e quant’altro. Senza il motore semantico le correlazioni sono pensate durante l’indicizzazione dei dati, con il supporto semantico occorre conoscere il modello e durante la ricerca navigare il grafo per un adeguato numero di livelli. Un’eventuale cambio di correlazioni porta da un lato a dover modificare tutti i dati indicizzati, dall’altro a cambiare solamente il modello semantico.
Le performance cambiano. Il supporto semantico risulta meno performante in quanto deve risolvere i livelli di navigazione del grafo. I dati sono denormalizzati in entrambi i casi, garantendo le prestazioni su grosse moli di dati. Si tratta di un piccolo costo da pagare per avere una elevata dinamicità nell’aggregazione dei dati.
Per il POC che abbiamo implementato abbiamo usato:
- Virtuoso come storage (Triple Store), che fornisce anche un endpoint SPARQL;
- SPARQL come linguaggio di interrogazione;
- OWL / RDF come linguaggio per la modellazione delle informazioni di dominio (modello);
- JAVA per il front-end.
Dal punto di vista architetturale Virtuoso rappresenta lo strato di persistenza, mentre il front-end Java implementa il layer di presentazione, in cui presentiamo dinamicamente le informazioni ricercate, un layer di logica applicativa che permette di attuare:
- logiche di autorizzazione;
- logiche autenticazione;
- logiche di reperimento di dati per contestualizzare i risultati della ricerca;
- un layer di accesso ai dati.
Per quanto riguarda la presentazione Google style delle informazioni, oltre ad elencare i dati e a creare i “link” per aprirli nei corrispondenti applicativi, è stato anche introdotto un sistema che mostra dinamicamente le informazioni correlate al singolo risultato della ricerca, in modo tale da contestualizzarlo, ampliarlo e facilitare quindi l’operatore nell’individuare l’informazione di suo interesse. Cercando ad esempio “Mario Rossi”, oltre al nome ed il cognome vengo mostrati il codice fiscale, il luogo di residenza e l’azienda pressa la quale lavora.
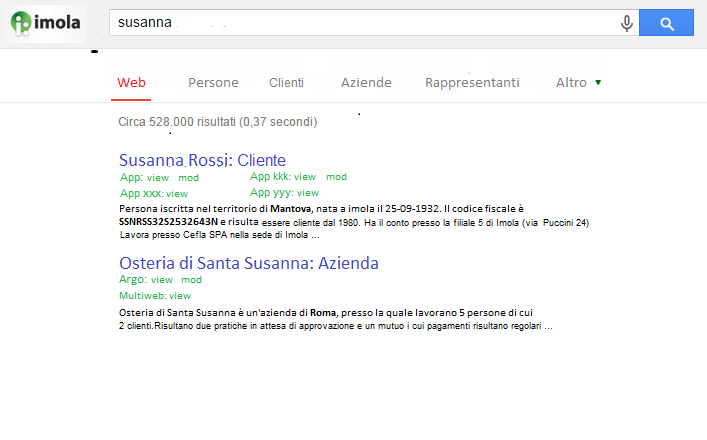
Il Proof Of Concept (POC) è stato realizzato in 10-15 giornate, avendo una piena conoscenza del dominio. Il cliente ha apprezzato il POC, che verrà evoluto ampliando il numero di concetti all’interno del modello e la quantità di informazioni presenti, modificando di conseguenza l’interfaccia grafica.
Andrea Ravagli
Francesco Panico
Normanno Cacciari