Carneade. Chi era costui? All’inizio dell’ottavo capitolo dei Promessi Sposi, Alessandro Manzoni introduce la figura di Don Abbondio intento a domandarsi chi fosse mai Carneade.
Purtroppo, di Don Abbondio che si occupano a vario titolo di GDPR, se ne incontrano parecchi. Capita spesso di scontrarsi con chi deve gestire o tutelare i dati personali e aziendali e che molte volte sembra ricordare, più per sentito dire che per reale comprensione del concetto, quanto è indicato nel Regolamento europeo per la Protezione dei dati personali (Reg. UE 679/2016: GDPR).
Il bianchetto non è una misura tecnica
Qualche mese fa il Garante per la protezione dei dati personali ha sanzionato l’Azienda sanitaria locale di Bari con una somma di 50.000 € indicando che: “L’uso del pennarello nero o del bianchetto non rappresenta una modalità efficace per rendere anonimi i dati personali degli utenti”. La ASL aveva pubblicato sul proprio portale web istituzionale centinaia di informazioni sullo stato di salute nella sezione del sito “Parlano bene di noi”. Sebbene l’intento fosse lodevole e volto ad attestare l’apprezzamento dei servizi sanitari offerti, il metodo scelto non è certo stato quello più adeguato. La ASL di Bari ha pubblicato documenti contenenti dati anagrafici e soprattutto informazioni relative allo stato di salute degli interessati che avevano usufruito dei servizi dell’ASL. Dettagli clinici degli interventi, terapie, prestazioni mediche, anamnesi, diagnosi: dati personali di tipo particolare (art. 9 del GDPR). Per maggiore garanzia di veridicità l’ASL ha pubblicato le scansioni delle lettere originali semplicemente sbianchettate o mascherando alcuni dati con un pennarello nero.
Quindi i dati personali risultavano facilmente intellegibili, vanificando così il goffo tentativo di rendere i dati anonimi.
Nella ingiunzione il Garante Privacy stigmatizza il pressapochismo adottato dall’ente: “La procedura di cancellazione manuale con pennarello o con bianchetto, per sua natura imprecisa e non definitiva, non può essere definita idonea a rendere anonime le informazioni personali degli interessati, né può definirsi una procedura di pseudonimizzazione”.
Facciamo un po’ di chiarezza
All’articolo 4 comma 5 il GDPR definisce la pseudonimizzazione come “il trattamento dei dati personali [deve avvenire] in modo tale che i dati personali non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive, a condizione che tali informazioni aggiuntive siano conservate separatamente e soggette a misure tecniche e organizzative intese a garantire che tali dati personali non siano attribuiti a una persona fisica identificata o identificabile”.
Purtroppo, cosa si intenda per pseudonimizzazione non è sempre chiaro, soprattutto inquadrandone il significato nell’ambito del GDPR.
In generale si può definire come pseudonimizzazione il processo di de-associazione dell’identità di un interessato dai dati personali trattati. Il processo può essere eseguito sostituendo uno o più identificativi personali, che possono consentire l’identificazione di un soggetto, con pseudonimi.
Due standard ISO (ISO/TS 25237:2017 e ISO/IEC 20889:2017) definiscono la pseudonimizzazione come “un particolare tipo di anonimizzazione” in cui si rimuove l’associazione con l’interessato e si aggiunge una associazione tra un set di informazioni con uno o più pseudonimi. Proprio in ottica GDPR, la pseudonimizzazione serve a nascondere le informazioni che identificherebbero direttamente la persona fisica (interessato) mediante un set di pseudonimi. Mantenendo però l’associazione tra l’identificativo originale e gli pseudonimi viene garantita una successiva re-identificazione della persona fisica.
La pseudonimizzazione non è una falsa anonimizzazione
Lo standard ISO/TS 25237:2017 indica che l’anonimizzazione è il processo con cui i dati personali sono irreversibilmente alterati, cosicché un soggetto non sia più identificabile né direttamente né indirettamente. Anche il NIST, nel suo glossario, lo definisce come “il processo che rimuove l’associazione tra un set di dati ed il soggetto cui i dati appartengono”.
In parole più semplici: un set anonimizzato di dati non consente l’identificazione della persona fisica cui i dati pertengono, e quindi un set di dati anonimizzato non è più soggetto alle indicazioni del GDPR.
Viceversa, i dati pseudonimizzati non sono anonimi. Nella pseudonimizzazione si introduce l’associazione di un set di identificativi personali con pseudonimi, e quindi la re-identificazione è possibile. In sostanza, la pseudonimizzazione su un set di dati personali, mediante l’associazione identificativi-pseudonimi, fa sì che il set risulti ancora un set di dati personali, e quindi ancora soggetto ai principi di protezione espressi dal GDPR.

Quale tecnica di pseudonimizzazione adottare?
Un valido aiuto all’interpretazione, proprio in ottica di adozione al GDPR, è dato da un documento di ENISA in cui sono descritte in dettaglio le differenti tecniche di pseudonimizzazione inquadrandole nel contesto dell’utilizzo, cioè dello specifico trattamento dei dati personali, e di conseguenza nel contesto di un approccio sempre volto alla riduzione del rischio.
La giusta pseudonimizzazione deve poter assolvere a due dettami:
- gli pseudonimi non dovrebbero consentire una facile re-identificazione da parte di figure non autorizzate
- non deve essere banale per un non autorizzato riprodurre gli pseudonimi.
Con il termine “non autorizzato” si intende una figura terza che non sia il data controller (o il titolare secondo la terminologia GDPR) o uno dei data processor (responsabile).
Lo stesso documento dell’ENISA suggerisce le tecniche di creazione di pseudonimi mediante Hashing senza chiave o con chiave o anche la cifratura come pseudonimizzazione:
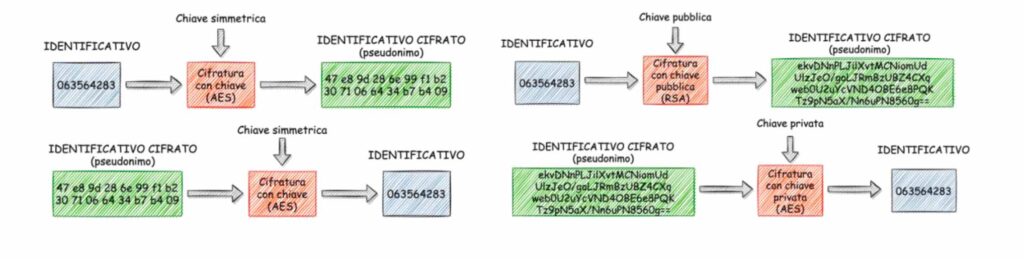
A destra: creazione di pseudonimo mediante cifratura con chiavi asimmetriche
L’identificativo originario è cifrato creando così lo pseudonimo o con chiavi simmetriche o asimmetriche (chiave pubblica e privata).
ENISA riporta anche altre tecniche assimilabili alla pseudonimizzazione, ma per ciascuna è bene ricordare sempre il contesto e il livello di protezione (sicurezza) che si vuole ottenere, anche perché nessuna di queste assolve appieno i requisiti richiesti:
- mascheramento
- scrambling
- bluring
Ciascuna di queste tecniche è indubbiamente valida, ma è adottabile solo nel contesto e con lo scopo che si intende raggiungere.
Concludendo
La pseudonimizzazione è una accettata metodologia di de-identificazione che ha riguadagnato consenso e visibilità con l’avvento del GDPR che la ha esplicitamente elencata, come meccanismo di data protection “by design”.
Proprio nel contesto del GDPR la pseudonimizzazione può innescare il rilassamento di alcuni obblighi in capo al titolare purché siano appropriatamente utilizzati.
I titolari dei trattamenti debbono adottare la Data Protection con un approccio by design nei loro processi. Così facendo possono applicare le corrette tecniche di pseudonimizzazione dei dati.
Per contro gli enti regolatori dovrebbero promuovere l’impiego della pseudonimizzazione come protezione dei dati a favore di elaborazioni in ottica GDPR.
